Modularizing Magic Equations in a Codebase
2022-03-22
I’ve spent the last two and a half years working with the Michigan Solar Car Team, where we design, build, and test the world’s fastest and most efficient solar-powered racecars. The strategy/software division I work with develops simulation models, optimizations, and other software products to aid engineering divisions and determine our on-race strategy. I’ll try to write about the fun things we work with at some point! Solar car strategy is pretty close to being an NP-Hard problem.
In late 2020, I developed a C++ library to modularize and compute piecewise polynomials of a single variable, and I’ve been meaning to produce a comprehensive document detailing my process since. We tend to use such magic equations to abstract/simplify physics calculations in higher-level simulations. Here’s the result of recapping (and rewriting!) this library over the course of a few days.
Representing Piecewise Polynomials in Code
Background
At some point in 2020, one of our solar car engineering teams requested a new feature for a physics model integrated in our race simulator. In summary, the team wanted the ability to model some car-related coefficients as piecewise functions of a single variable.
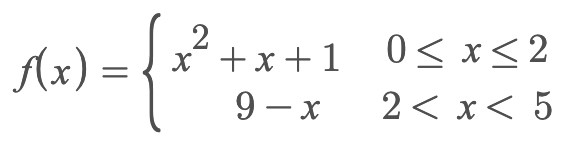
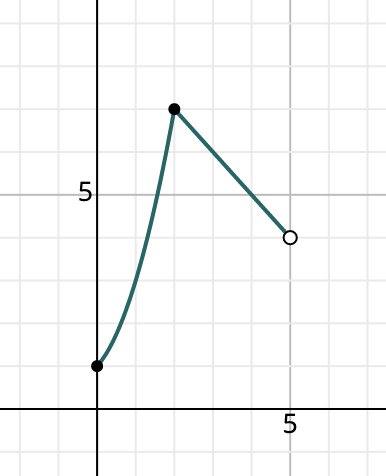
We usually want such coefficients to either be backed up by another set of underlying formulae or some empirical evidence. However, this isn’t always possible, and sometimes we just have to “trust the tools” and the numerical model/data they output (while still understanding the method and results!).
In this case, there was no underlying formula we could use, and the engineering team provided us with a set of discrete data points (for the sake of simplicity here, in a 2D space). We’d need to find a best-fit function, some kind of spline, or an interpolation scheme, to use this discrete data over a continuous input/output space. Back then, we decided to construct manual splines using piecewise polynomials so we could retain control over the shapes and bounds of our functions. I believe we use a type of spline interpolation today.
For a barebones implementation, we got away with simply hardcoding the bounds and functions in our system of equations.
1if (x >= lowerBound1 && x < upperBound1)
2{
3 y = a0 + a1 * x + a2 * x * x;
4}
5else if (x >= lowerBound2 && x < upperBound2)
6{
7 y = b0 + b1 * x + b2 * x * x;
8}
9else
10{
11 y = c0;
12}
However, then came the kicker: this system of equations could change for a different part used, a different car, or even different environmental conditions!
Since all the aforementioned components are modularized in our simulation software , these systems of polynomials would also need to be modularized. I was lazy initially and simply implemented different functions in code to compute different systems, using our input config files to specify which function was to be used. But littering our codebase with magic numbers was obviously a bad idea, so I kept thinking about better solutions in the back of my mind. Imagine changing the tire on your car with a simple software config change. Welcome to the metaverse.
Software Requirements
In short, we wanted a solution to:
- Work with our existing C++ codebase
- Be “modular”, meaning a system of equations is independent from our code
- Be somewhat readable without needing additional software
- Not require a lot of code complexity in terms of parsing/handling
Since all of our software config files are formatted as JSON (and we use nlohmann::json to parse them), I thought it would be neat to stick to this family for our representation of a system of equations.
Math Requirements
Since our manual curve-fitting process was fairly simple, our math requirements were simple too:
- Support using a floating-point input variable to an expression with an m-degree polynomial as the numerator, and an n-degree polynomial as the denominator
- Enable using piecewise functions where each piece is defined with floating-point lower and upper bounds with configurable exclusivity/inclusivity
The Solution
After having some very complicated ideas for recursive representations of any type of equation in the universe (my brain was truly “creative” back then), I whittled our requirements down to their bare minimums and came up with this JSON schema for a piece in the system of equations:
1{
2 "lower_bound": 0.0,
3 "lb_inclusive": true,
4 "upper_bound": 1.0,
5 "ub_inclusive": false,
6 "numerator": {
7 "powers": [0, 1],
8 "coefficients": [5, 10]
9 },
10 "denominator": {
11 "powers": [0],
12 "coefficients": [2]
13 }
14}
I think it’s pretty easy to read what’s going on here. A complete system would be represented as a list of such pieces, each with their own non-overlapping bounds. It may not be the prettiest solution, but it gets the job done.
One design decision I made was to use “parallel lists” (I’m not sure if there’s a formal term for this) for the powers and coefficients in a numerator/denominator. That is, in computing an expression, the input variable would get raised to the power specified at the i-th index of the powers list and be multiplied by the coefficient at the same i-th index of the coefficients list. I felt that making this power-coefficient pair yet another dict in the representation would make the representation heavy.
In the happy case, it’s super easy whip up a library to compute an expression based on this representation. Given an input x, just iterate through the list of pieces, find the piece whose bounds it fits in, and compute the numerator/denominator as specified.
Safety: Simple Violations
There are some simple safety violations we must handle:
- Bounds are inclusive by default
Upper Bound < Lower Boundis fatal(Upper Bound == Lower Bound)and((Upper Bound is exclusive) or (Lower Bound is exclusive))is fatalDenominator == 0is fatal- An undefined numerator
anddenominator gets set to 0 - An undefined numerator
xordenominator gets set to 1 len(powers) != len(coefficients)is fatal
Safety: Undefined Regions
It’s okay to have undefined regions in the input space as long as the library throws a relevant error or indication of an invalid request when an input value is in an undefined region.
Safety: Overlapping Bounds
How does this simple implementation behave when two pieces have overlapping bounds (unintentionally, of course)? There’s always that slight possibility of user error and ensuring bounds don’t overlap seems like a good safety check for such a software library.
A correct but naive solution would be to compare a candidate piece against all the pieces before it and ensure the bounds don’t overlap. This could be done at the time of construction when JSON is being deserialized to *object in language of choice*.
However, in late 2020 I was just done with the Data Structures & Algorithms class in our computer science curriculum at Michigan, and something seemed off. If every candidate was compared against its predecessors, that’s a total of Σ(n-1) checks being done for a system with n pieces. Big-O fans out there will note that this ends up with a worst-case complexity approaching O(n²). Ouch.
People I’ve worked with will know that I usually do not obsess over time/space complexity, but in this case tackling it solved a nice problem as you’ll see below!
Ordering Ranges of Numbers
The naivety of the simple safety check for overlapping bounds exposes an area for optimization. In fact, the optimization would not only improve the time complexity of the safety check, but also the time complexity of indexing into the “list of pieces” when calculating the output for an input value. Who doesn’t like feeding two birds with one scone?!
I previously stated that:
- A piece is valid for a range defined by an upper and lower bound across the input space
- The bounds of a range are real numbers
- No two pieces in a system may have overlapping regions
These led me to conclude that we can create a total ordering given a valid (comparable) set of numeric ranges. Simply put, it would be reasonable to state:
[0.0, 1.5) < [2.0, 2.5) < [3.0, 3.5) < [3.5, 3.5] < (3.5, 4.0] < (4.0, 7.5)
We also know that ordered unique data can be represented as a binary tree. The time complexity of searching a balanced binary tree is the well-known O(log n). Rather than express a system as a linear structure comprising pieces, we can now represent a system as a tree of pieces ordered by their bounds (note we rely on the underlying tree implementation for balancing).
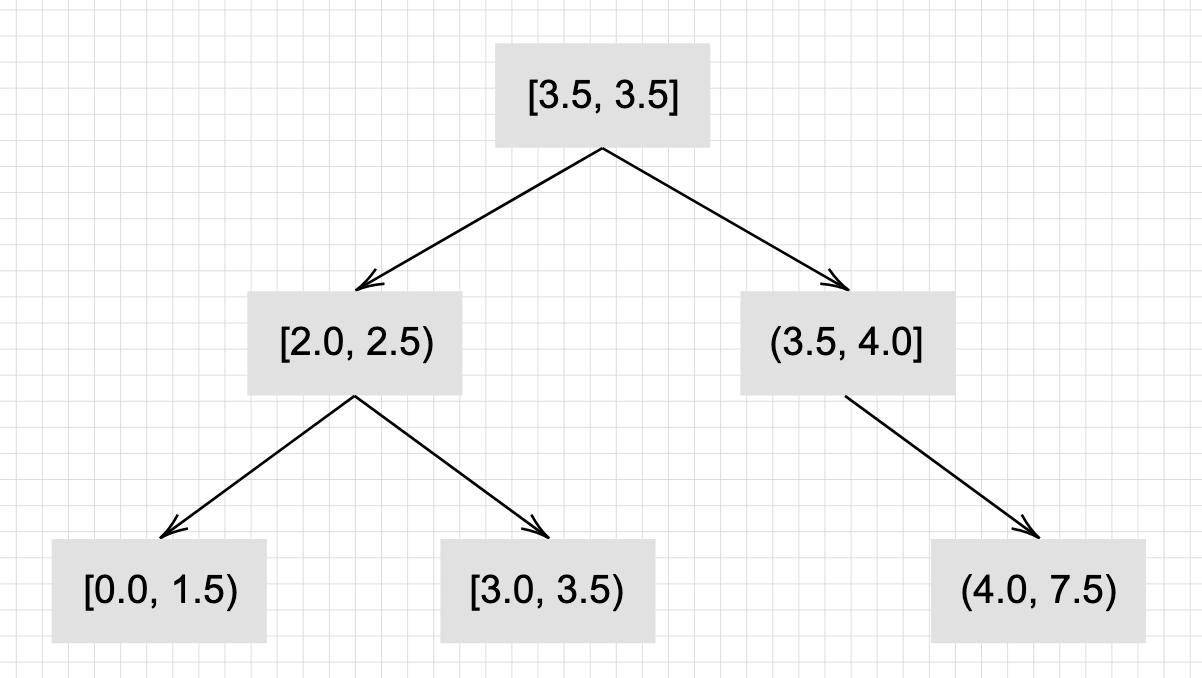
Now, all that’s needed is a comparison function for this “numeric range” type. Additionally, the same comparator could handle detecting overlapping ranges since it’s not really possible to order them, thus simplifying the safety check implementation!
Nominal Truth Tabling
I figured that a truth table of combinations could help determine what this comparison function should look like
. In general, comparing two numbers presents three results: <, =, or >. However, with two numeric elements in a range and options for inclusive/exclusive bounds, things become a little messier.
Whoa, I actually ended up following test-driven development for once! It was very pleasant, and I should try this more often.
Say we are given the range [0, 1] and want to see if [A, B] < [0, 1] or [0, 1] < [A, B]:
| A | B | [A, B] < [0, 1] | [0, 1] < [A, B] |
|---|---|---|---|
| -0.5 | -0.25 | true | false |
| -0.5 | 0 | invalid | invalid |
| 0 | 0.5 | invalid | invalid |
| 0 | 1 | false | false |
| 0.5 | 1 | invalid | invalid |
| 1 | 1.25 | invalid | invalid |
| 1.25 | 1.5 | false | true |
Making a bound exclusive instead of inclusive doesn’t fundamentally change much. If the ranges being compared share the same boundary, flipping their inclusive/exclusive attribute would probably just move the case up or down a row in this truth table.
Truth Tabling For a “Scalar”
Note that we have to make an exception for indexing though. Say we are given an input value of 0.5 and are told to find the range that contains this value. In this implementation, we construct a “scalar”, i.e. [0.5, 0.5] for comparison with the other ranges in the tree. By converting a single input value to a numeric range, we can continue to use std::map::operator[] (that uses our comparator function) to do the dirty work for us. However, the truth table changes in this scenario:
| A | B | [A, B] < [0.5, 0.5] | [0.5, 0.5] < [A, B] |
|---|---|---|---|
| -0.5 | 0 | true | false |
| 0 | 0 | true | false |
| 0 | 0.5 | false | false |
| 0.5 | 0.5 | false | false |
| 0.5 | 1 | false | false |
| 0 | 1 | false | false |
| 1 | 1 | false | true |
| 1 | 1.25 | false | true |
Note the rows in bold. In old-school C++, two objects A and B are considered equal when
(A < B) == false && (B < A) == false
Since any of the ranges [0, 0.5] / [0.5, 0.5] / [0.5, 1] / [0, 1] would include the value 0.5, the comparator returning false irrespective of lhs/rhs placement would allow us to find the range that contains a scalar input value. Likewise, comparing two identical ranges (with the same inclusivity attributes too) should return false.
Code
The code for the comparator is a little more verbose than I’d like, but my hope is it maintains correctness while not sacrificing readability too much. It initially looked like “space shuttle style” code, but I was able to condense it a fair amount.
1bool operator() (const NumericRange<T> &lhs, const NumericRange<T> &rhs) const
2{
3 const bool lhs_is_scalar = (lhs.lb == lhs.ub);
4 const bool rhs_is_scalar = (rhs.lb == rhs.ub);
5
6 if (lhs_is_scalar && rhs_is_scalar)
7 {
8 return (lhs.lb < rhs.lb);
9 }
10 else if (lhs_is_scalar)
11 {
12 return ((lhs.lb < rhs.lb) || (lhs.lb == rhs.lb && !rhs.lb_inclusive));
13 }
14 else if (rhs_is_scalar)
15 {
16 return ((lhs.ub < rhs.lb) || (lhs.ub == rhs.lb && !lhs.ub_inclusive));
17 }
18 else
19 {
20 if (lhs.lb == rhs.lb && lhs.lb_inclusive == rhs.lb_inclusive
21 && lhs.ub == rhs.ub && lhs.ub_inclusive == rhs.ub_inclusive)
22 {
23 return false;
24 }
25 else if ((lhs.ub < rhs.lb) ||
26 (lhs.ub == rhs.lb && !(lhs.ub_inclusive && rhs.lb_inclusive)))
27 {
28 return true;
29 }
30 else if ((lhs.lb > rhs.ub) ||
31 (lhs.lb == rhs.ub && !(lhs.lb_inclusive && rhs.ub_inclusive)))
32 {
33 return false;
34 }
35 else
36 {
37 throw std::runtime_error(
38 "Invalid comparison between overlapping ranges");
39 }
40 }
41} /* bool operator() */
The repository for numeric_range also contains an example program which uses a NumericRange object as the key for an std::map. The same idea is extended to the original problem we’re trying to solve, where we use numeric ranges to sort and index the pieces in a system of piecewise polynomial equations!
Putting it Together
Thus, we used the concept of a numeric (or really just a type with an innate ordering attached to it) to implement a numeric range. Numeric ranges are used to implement the base of an application like piecewise equations.
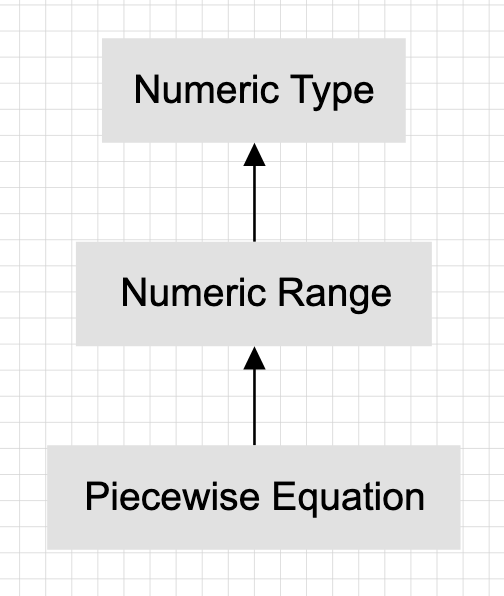
Earlier this year our team found another use for “numeric ranges” and their application in indexable containers. Thus, I converted the numeric range implementation to an independent library that can be found here. Using templates feels a little weird here (let me know if you have ideas for restricting it to numeric types!), so I guess I’ll just not provide any guarantees for bound types that don’t have a well-defined operator<.
The JSON Equation library simply implements an std::map with key type NumericRange and value type PolynomialEquation under the hood. Some additional functions were added for parsing and calculation. The repository can be found here. Usage looks like:
1ifstream infile("really_cool_system.json");
2JSONEquation really_cool_system(infile);
3
4// Calculate the output value with input x = 0
5auto f0 = really_cool_system.calculate(0);
6if (f0.has_value())
7 std::cout << f0.value();
8else
9 std::cout << "0 not included in any pieces' ranges" << std::endl;
10
11// Or use the shorthand operator(), equivalent to calling calculate()
12auto f1 = really_cool_system(1);
Using independent JSON files also worked well with our team’s version control and data backup practices. Overall, not clouding our code with magic math expressions felt like a nice win.
Final Notes
This post definitely turned out longer than I expected, and I feel like such simple concepts don’t need this much vertical space. On the bright side, this post serves as indisputable documentation for when someone (including myself after a break) looks at my code and inevitably goes wtf.
If you’ve found a mistake or area for improvement in my design, methodology, or explanations, please feel free to let me know, or open an issue or PR in the respective GitHub repos!
Thanks to my friends at the Michigan Solar Car Team for reviewing my work and pushing me to explore interesting concepts like this!
~ Amal